| Autor |
Nachricht |
estrella
Anmeldungsdatum: 24.10.2004
Beiträge: 17
|
 Verfasst am: 11. Dez 2004 19:02 Titel: m.H. der Codesonne die Basensequenz übersetzen Verfasst am: 11. Dez 2004 19:02 Titel: m.H. der Codesonne die Basensequenz übersetzen |
 |
|
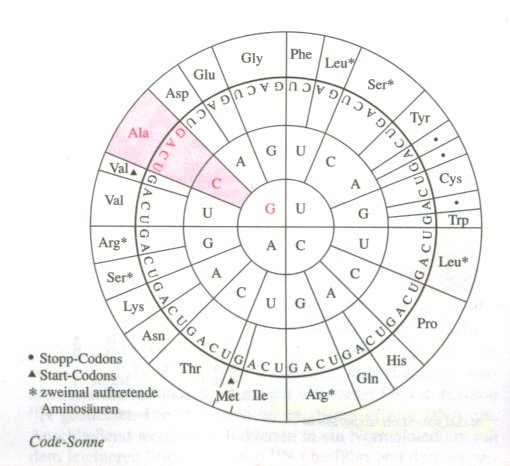
Übersetze mithilfe der Codesonne (Abb. von innen nach außen lesen) die Basensquenz des unten dargestellten DNA-Stückes unter Angabe des Zwischenproduktes in der Aminosäuresequenz des entsprechendes Peptids.
1 2 3 4 5 6 7 8 9 10 11 12
A T A T C C A G C T C G
Kann mir jemand helfen? ich weiß gar nicht, was ich machen muss.
| Beschreibung: |
|
| Dateigröße: |
43.92 KB |
| Angeschaut: |
51531 mal |
|
|
|
 |
chefin
Organisator
Anmeldungsdatum: 28.04.2004
Beiträge: 1549
Wohnort: Oberhausen
|
| Verfasst am: 11. Dez 2004 19:35 Titel: |
|
|
Ist doch ganz einfach: Du musst deinen DNA-Strang in den komplementären RNA-Strang übersetzen und dir dann auf der Code-Sonne die entsprechenden Aminosäuren heraussuchen.
Beispiel: TATGCGATGCGT sei dein DNA-Strang, dann ist die komplementäre RNA AUACGCUACGCA
Die Code-Sonne wird von innen nach aussen gelesen: Also AUA entspricht Ile, CGC entspricht Arg, UAC entspricht Tyr und GCA entspricht Ala. Mein Polypeptid wäre demnach Ile-Arg-Tyr-Ala Ich habe natürlich ein anderes Stück DNA benutzt als Deins, damit du auch überprüfen kannst, ob du meine Erklärung verstanden hast. 
_________________
Wissen ist Macht, Nichtwissen macht machtlos |
|
|
chefin
Organisator
Anmeldungsdatum: 28.04.2004
Beiträge: 1549
Wohnort: Oberhausen
|
| Verfasst am: 11. Dez 2004 19:36 Titel: |
|
|
Ist doch ganz einfach: Du musst deinen DNA-Strang in den komplementären RNA-Strang übersetzen und dir dann auf der Code-Sonne die entsprechenden Aminosäuren heraussuchen.
Beispiel: TATGCGATGCGT sei dein DNA-Strang, dann ist die komplementäre RNA AUACGCUACGCA
Die Code-Sonne wird von innen nach aussen gelesen: Also AUA entspricht Ile, CGC entspricht Arg, UAC entspricht Tyr und GCA entspricht Ala. Mein Polypeptid wäre demnach Ile-Arg-Tyr-Ala Ich habe natürlich ein anderes Stück DNA benutzt als Deins, damit du auch überprüfen kannst, ob du meine Erklärung verstanden hast.
_________________
Wissen ist Macht, Nichtwissen macht machtlos |
|
|
estrella
Anmeldungsdatum: 24.10.2004
Beiträge: 17
|
| Verfasst am: 11. Dez 2004 20:24 Titel: |
|
|
Also zu meinem Beispiel die komplementäre RNA wäre
UAU AGG UCG AGC
Tyr Arg Ser Ser wäre das Polypeptid
Sind Start-und Stoppcodons bei solchen Aufgaben auch zu beachten, können die was am Resultat ändern?
Wenn durch radiaktive Bestrahlung das 2. Nukleotid herausgebrochen wird, das die Base Thymin enthält, dann wäre die komplementäre RNA so, oder?:
UUA GGU CGA GC
Leu Gly Arg Ala
Was bedeuten die zweimal aufeinandertretenden Aminosäuren in der Codesonnen-Abbildung?
|
|
|
Der Zar von Russland
Gast
|
| Verfasst am: 11. Dez 2004 21:23 Titel: |
|
|
| chefin hat Folgendes geschrieben: | Ist doch ganz einfach: Du musst deinen DNA-Strang in den komplementären RNA-Strang übersetzen und dir dann auf der Code-Sonne die entsprechenden Aminosäuren heraussuchen.
Beispiel: TATGCGATGCGT sei dein DNA-Strang, dann ist die komplementäre RNA AUACGCUACGCA
Die Code-Sonne wird von innen nach aussen gelesen: Also AUA entspricht Ile, CGC entspricht Arg, UAC entspricht Tyr und GCA entspricht Ala. Mein Polypeptid wäre demnach Ile-Arg-Tyr-Ala Ich habe natürlich ein anderes Stück DNA benutzt als Deins, damit du auch überprüfen kannst, ob du meine Erklärung verstanden hast. |
Was soll der Scheiß????
Die Konvention der IUB lautet, dass sämtliche Nucleinsäuresequenzen von 5' nach 3' geschrieben werden. Somit wäre in deinem Beispiel der erste DNA-Strang ja in 3'-5'-Richtung hingekritzelt, was aber nicht den Normen entspricht - aus gutem Grund!
In ALLEN Sequenzdatenbanken ist der codierende, also unmittelbar der mRNA-Sequenz eines transkribierten Genes entspr. DNA-Strang in 5'-3'-Richtung angegeben (U wird natürlich gegen T ausgetauscht und das backbone interessiert bei der Schreibweise net ...).
Demzufolge ist die Aminosäuresequenz JEDES DNA-Stranges sofort mit Hilfe einer Tabelle oder der Code-Sonne ablesbar (T gegen U tauschen). Im Übrigen funktionieren sämtliche Programme zum Übersetzen einer Basensequenz auf dieselbe Weise!
Es sei denn, es wäre etwas anderes in einer Aufgabe z. B. angegeben!!!!
Und man probiere mal zum Spaß dieses Übersetzungstool:
http://www.expasy.org/tools/dna.html
Ich lach mich allmählich schlapp!
|
|
|
Der Zar von Russland
Gast
|
| Verfasst am: 11. Dez 2004 21:55 Titel: |
|
|
Nur vorsorglich, bevor noch Ausreden kommen:
In dem Ausgangsposting von estrella fehlen die Kennzeichnungen der 5'- und 3'-Enden, so dass eben nicht ersichtlich ist, dass dieser Strang "rückwärts" gelesen werden soll! Somit kann man nur von einer 5'-3'-Richtung ausgehen.
|
|
|
estrella
Anmeldungsdatum: 24.10.2004
Beiträge: 17
|
| Verfasst am: 11. Dez 2004 22:56 Titel: |
|
|
@Der Zar von Russland
Habe ich meine Aufgabe nicht richtig gelöst?
| Der Zar von Russland hat Folgendes geschrieben: | | chefin hat Folgendes geschrieben: | Ist doch ganz einfach: Du musst deinen DNA-Strang in den komplementären RNA-Strang übersetzen und dir dann auf der Code-Sonne die entsprechenden Aminosäuren heraussuchen.
Beispiel: TATGCGATGCGT sei dein DNA-Strang, dann ist die komplementäre RNA AUACGCUACGCA
Die Code-Sonne wird von innen nach aussen gelesen: Also AUA entspricht Ile, CGC entspricht Arg, UAC entspricht Tyr und GCA entspricht Ala. Mein Polypeptid wäre demnach Ile-Arg-Tyr-Ala Ich habe natürlich ein anderes Stück DNA benutzt als Deins, damit du auch überprüfen kannst, ob du meine Erklärung verstanden hast. |
Was soll der Scheiß????
Die Konvention der IUB lautet, dass sämtliche Nucleinsäuresequenzen von 5' nach 3' geschrieben werden. Somit wäre in deinem Beispiel der erste DNA-Strang ja in 3'-5'-Richtung hingekritzelt, was aber nicht den Normen entspricht - aus gutem Grund!
In ALLEN Sequenzdatenbanken ist der codierende, also unmittelbar der mRNA-Sequenz eines transkribierten Genes entspr. DNA-Strang in 5'-3'-Richtung angegeben (U wird natürlich gegen T ausgetauscht und das backbone interessiert bei der Schreibweise net ...).
Demzufolge ist die Aminosäuresequenz JEDES DNA-Stranges sofort mit Hilfe einer Tabelle oder der Code-Sonne ablesbar (T gegen U tauschen). Im Übrigen funktionieren sämtliche Programme zum Übersetzen einer Basensequenz auf dieselbe Weise!
Es sei denn, es wäre etwas anderes in einer Aufgabe z. B. angegeben!!!!
Und man probiere mal zum Spaß dieses Übersetzungstool:
http://www.expasy.org/tools/dna.html
Ich lach mich allmählich schlapp!
|
|
|
|
Der Zar von Russland
Gast
|
| Verfasst am: 11. Dez 2004 23:37 Titel: |
|
|
Ich würde die Aufgabe gemäß der Nomenklatur so verstehen, dass die Basensequenz lautet:
5'-ATATCCAGCTCG-3'
Dies ist der codierende Strang. Der nichtcodierende template-Strang wäre komplementär und an DIESEM wird die mRNA bzw. die Prä-mRNA synthetisiert.
Somit lautet die mRNA:
5'-AUAUCCAGCUCG-3'
Übersetzt im ersten Leserahmen:
Ile-Ser-Ser-Ser
|
|
|
Karon
Organisator

Anmeldungsdatum: 06.11.2004
Beiträge: 2344
Wohnort: Hessen
|
| Verfasst am: 11. Dez 2004 23:44 Titel: Re: m.H. der Codesonne die Basensequenz übersetzen |
|
|
Hallo estrella!
Ich denke schon, dass du die Aufgabe richtig gelöst hast.
Schließlich ist ja in der Aufgabenstellung von einem "Zwischenprodukt" die Rede (also der komplementären RNA).
Wenn der Strang nach der Konvention aufgeschrieben wäre, wie der Zar es meint, wäre ja gar kein Zwischenprodukt nötig.
(Allerdings muss man sagen, dass man trotzdem ein Zwichenprodukt aufschreiben könnte, indem man einfach alle T's gegen U's austauscht...)
| estrella hat Folgendes geschrieben: | | Übersetze mithilfe der Codesonne (Abb. von innen nach außen lesen) die Basensquenz des unten dargestellten DNA-Stückes unter Angabe des Zwischenproduktes in der Aminosäuresequenz des entsprechenden Peptids. |
Frag doch einfach nochmal deinen Lehrer, ob denn jetzt alle Sequenzangaben in seinen Aufgaben nach der Konvention aufgeschrieben sind oder nicht. Das würde hier enorm weiterhelfen.
(Bei mir waren damals in der Schule auch nicht immer alle Sequenzen streng nach Konvention aufgeschrieben!)
Grüße,
Karon
@ Zar:
Spar dir doch einfach mal deine dämlichen Seitenhiebe auf PISA! 
Das ist echt nervig und motiviert Schüler ganz sicherlich nicht, wenn sie von vornherein als dumm hingestellt werden! Jeder hat schließlich mal "klein" angefangen oder warst du schon immer so ein "Alleswisser"???
|
|
|
Der Zar von Russland
Gast
|
| Verfasst am: 12. Dez 2004 00:16 Titel: Re: m.H. der Codesonne die Basensequenz übersetzen |
|
|
| Karon hat Folgendes geschrieben: | Hallo estrella!
Ich denke schon, dass du die Aufgabe richtig gelöst hast.
Schließlich ist ja in der Aufgabenstellung von einem "Zwischenprodukt" die Rede (also der komplementären RNA).
Wenn der Strang nach der Konvention aufgeschrieben wäre, wie der Zar es meint, wäre ja gar kein Zwischenprodukt nötig.
(Allerdings muss man sagen, dass man trotzdem ein Zwichenprodukt aufschreiben könnte, indem man einfach alle T's gegen U's austauscht...)
| estrella hat Folgendes geschrieben: | | Übersetze mithilfe der Codesonne (Abb. von innen nach außen lesen) die Basensquenz des unten dargestellten DNA-Stückes unter Angabe des Zwischenproduktes in der Aminosäuresequenz des entsprechenden Peptids. |
Halt dich mit deinen beleidigenden Kommentaren in Zukunft zurück!
PISA war wohl an die Adresse der chefin gerichtet, die solch elementaren Aufgaben nicht mal richtig lösen kann (zudem ist auch noch ein Codon von der falsch übersetzt .......).
Zudem ist es doch wohl falscher Riesenunfug irgendeine Aufgabe mit Basensequenzen zusammenzuzimmern, in der doch in der Tat die Konventionen nicht eingehalten werden. Darf da jeder mal Rate mal mit Rosenthal spielen, oder wie denken sich die wehrten PädagogInnen das?
Frag doch einfach nochmal deinen Lehrer, ob denn jetzt alle Sequenzangaben in seinen Aufgaben nach der Konvention aufgeschrieben sind oder nicht. Das würde hier enorm weiterhelfen.
(Bei mir waren damals in der Schule auch nicht immer alle Sequenzen streng nach Konvention aufgeschrieben!)
Grüße,
Karon
@ Zar:
Spar dir doch einfach mal deine dämlichen Seitenhiebe auf PISA!
Das ist echt nervig und motiviert Schüler ganz sicherlich nicht, wenn sie von vornherein als dumm hingestellt werden! Jeder hat schließlich mal "klein" angefangen oder warst du schon immer so ein "Alleswisser"??? |
|
|
|
estrella
Anmeldungsdatum: 24.10.2004
Beiträge: 17
|
| Verfasst am: 12. Dez 2004 10:02 Titel: |
|
|
bin jetzt verwirrt durch die ganzen Streitgespräche.
Verstehe gar nichts mehr
|
|
|
chefin
Organisator
Anmeldungsdatum: 28.04.2004
Beiträge: 1549
Wohnort: Oberhausen
|
| Verfasst am: 12. Dez 2004 20:13 Titel: |
|
|
Hallo estrella, da du keine weiteren Angaben zu deinem Strang hast, ist das richtig so.
Der Zar hat heute mal wieder Ausgang. Dann lass ihn mal. Ich kanns ab, also, dass was du von ihm nicht verstehst, ignoriere einfach. Wenn die Antwort falsch ist, dann meld dich mit der von deinem Lehrer geforderten Antwort einfach wider hier. Dann wissen wirs alle. 
_________________
Wissen ist Macht, Nichtwissen macht machtlos |
|
|
Gast
|
| Verfasst am: 12. Dez 2004 20:19 Titel: |
|
|
Hallo allerseits,
es ist vielleicht nicht hilfreich, wenn sich noch jemand in diese Diskussion einmischt. Ich muss dem Zaren hier aber durchweg recht geben. Es ist nun einmal üblich, den DNA-Strang darzustellen, der der RNA-Sequenz entspricht, und zwar von 5-3. Daher sind die Angaben des Zaren absolut korrekt. Sollte Dein Lehrer den Matrizenstrang dargestellt haben ohne dies anzugeben, liegt der Fehler definitiv bei ihm.
|
|
|
|

